Sentence Transformers and Random Forests for Multilingual Sentiment Classification (or: The Dangers of Synthetic Data)

Summary¶
- At Egregious, we use a hybrid Sentence Transformer/random forest pipeline to classify sentiment for text across multiple languages
- This lets us classify sentiment across a wide range of languages quickly and accurately with minimal additional computational overhead
- Unfortunately, good quality labelled datasets for sentiment in multiple languages are sparse, and their labels are often not harmonised
- Trying to solve this problem by using exclusively synthetic data may cause more problems than it solves
Introduction¶
At Egregious, we analyse a lot of content from across the open web covering many different languages. This includes social media posts, comments, videos, and news stories which may come from any part of the world. We often don’t know what language content will be in ahead of time. Many social media platforms are multilingual but don’t tag posts by language. Even on forums where there is some user-driven categorisation, there’s usually no easily readable metadata to identify this, and there might be other languages mixed in. For instance, the /r/askspain community on reddit has a mixture of English and Spanish text.
All of this means that we need to handle multiple languages gracefully for common NLP tasks like entity recognition, semantic clustering, and sentiment analysis.
First, let’s look at our data ingest pipeline:
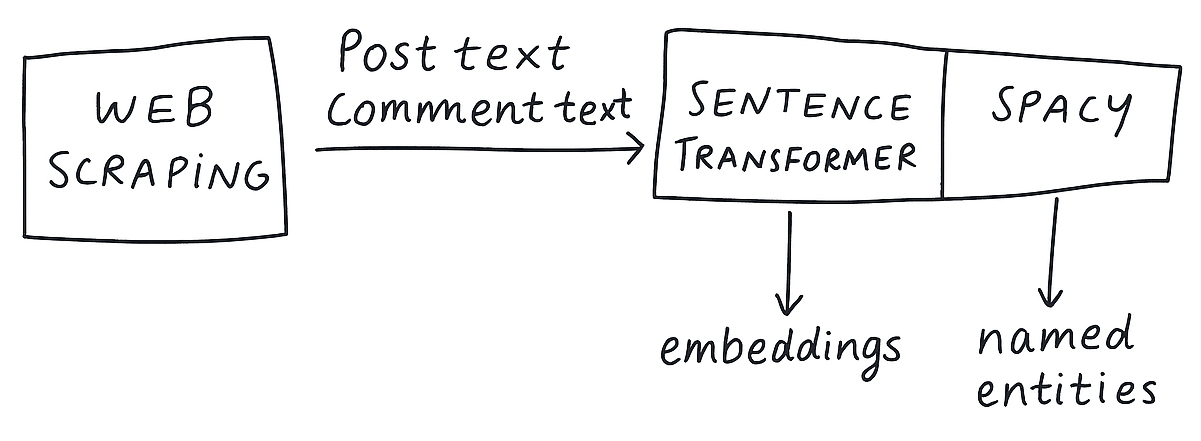
We calculate an embedding for each piece of text: chunking text, embedding each chunk, and then take the mean to create a centroid embedding. We also use a multilingual named entity recognition model from Spacy. Whilst there are multilingual sentence embedding models which allow you, for example, calculate semantic similarity between two texts in different languages, there are few ‘off the shelf’ multilingual sentiment classification models. Prior to this project, we were using the VADER model to classify the sentiment of text, which is only designed for English, motivating this project to investigate multilingual solutions.
The Sentiment Model Landscape¶
A search on Huggingface for sentiment models reveals a large number of specialised models, which can be deployed for individual languages, or small numbers of languages at a time. Oftentimes, they are developed by individual separate teams and trained on different sets of labels, making their results hard to compare. Multilingual models which support classification ‘out of the box’ are uncommon, and may only support a relatively low number of (often European) languages.
Alternatively, some true multilingual models are available. The one with the most supported langauges (that I could find) was tabularisai/multilingual-sentiment-analysis, which can handle 22 languages and is obviously popular with more than 300,000 downloads. Models like this were interesting to us due to how easy they would be to set up, but had some drawbacks, namely their computational expense and specialisation - we’d be running two transformer models to do different things instead of one. This could easily cause problems when quickly processing hundreds of thousands or millions of posts, some of which can be very large (e.g. the transcript of a 3 hour long video essay).
We get something for this cost: End-to-end transformer models are in general very effective for sentiment classification. Whilst we don’t want to spend hours processing each post as it arrives, we also want to get accurate classifications. This gives something of a tradeoff between using an off the shelf, accurate, but expensive model - or attempting to develop our own specialised (but efficient) in-house solution. In the text below, I’ll compare our approach that creates a model that leverages sentence embeddings to the tabularis model, to compare how popular transformer models compare to our hybrid sentence transformer based approach.
Our Approach¶
Given that we were already using transformers to calculate embeddings for text as it was ingested, we wanted to see if we could leverage this for sentiment classification. Some research suggests this is possible, such as this paper by Poornima and Priya, but no off the shelf classifier or similar technology.
Sentence transformers (also known as SBERT) calculate a sentence embedding, which represents the semantic meaning of a short piece of text. It is based on the BERT transformer model, which calculates individual word embeddings. SBERT models differ from standard BERT models in two important ways: First, they “[add] a pooling operation to the output of BERT / RoBERTa to derive a fixed sized sentence embedding.” Secondly, they are fine-tuned on a dataset of sentences after this pooling step has been added, so that the transformer model is specialised to produce a mean embedding for a whole sentence rather than individual words. This is important, because simply averaging the embeddings of each individual token produced by a BERT model was shown to give poor results.
Accordingly, two sentences with similar semantic content but different sentiments will be represented differently. For example, the two sentences:
- I like cheese
- I don’t like cheese
Will differ in their position in the embedding space thanks to the addition of the negation. Because BERT models learn a token, positional, and segment embedding which are added together, any change in embedding created by adding “don’t” will vary depending on the rest of the sentence. There however will likely be consistsent shifts which correspond to the concept of negation and other concepts related to the sentiment of a text.
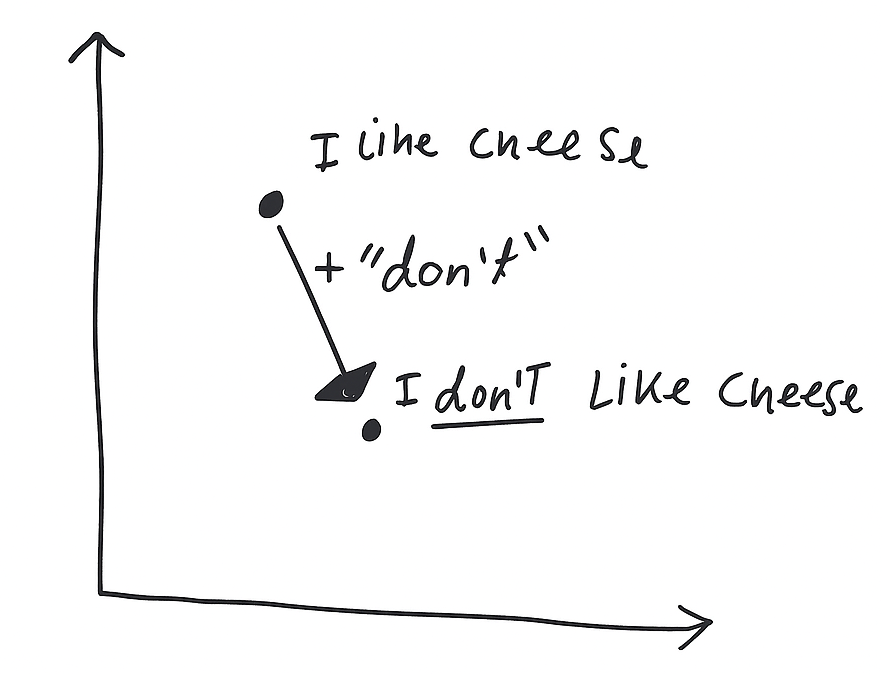
Intuitive representation of how adding a token can affect a sentence embedding. Notably adding the word “don’t” to another sentence in the won’t have the exact same effect.
We’re hoping we can use this difference to draw a decision boundary between positive, neutral, and negative sentiments. We can extend this to multiple languages thanks to the excellent addition to the original SBERT implementation; developing a multilingual model giving embeddings where “Vector spaces are aligned across languages, i.e., identical sentences in different languages are close”. This is an important property, as it implies that there should be language-independent differences between positive and negative text, though this may not be consistent across different language families and types.
Just as the introduction of a negation or affectively charged token can change the embedding of the whole sentence in English, so too should this effect persist into other languages.

Data¶
Unfortunately, there is no one single comprehensive large multilingual sentiment dataset. This forced us to combine and harmonise a number of different datasets together into a single large dataset. We found datasets for the following languages:
- Portuguese
- Indonesian
- Russian
- Japanese
- English
- Mandarin Chinese
- French
- Persian
- Italian
- Arabic
- Hindi
- Malay
- German
In some cases, labels were not directly harmonised (e.g. the ‘positivo’ class in the Portuguese dataset had to be changed to ‘positive’ to fit the others) and needed manual updates to fix these. It was also challenging to find good quality (especially where the labelling process is described) and large datasets in some languages, which is why only 13 are included, and the dataset sizes are inconsistent. Surprisingly to me, there were no real centralised repositories (at least that I could find) of multilingual labelled sentiment data.
Some were more numerous than others - for example the Portuguese dataset is much larger than any other language, so we down sampled the Portuguese texts to prevent significant imbalance. We also down sampled in each language and each sentiment class (positive, neutral, negative) so that the dataset was balanced across classes in every language, but some languages were over or under represented.
Methods and Models¶
We embedded all the text using the sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 model available on Huggingface. For texts longer than the maximum length of the input, we chunked the text and embedded each chunk before taking the average to calculate the centroid of the text in embedding space. We then used these embeddings to train the classifier models, so we can re-use our existing embeddings for sentiment classification.
We split the data into train/test/validate splits representing 50%/25%/25% respectively, and tried a number of models on the classification task. These were:
- Support Vector Machines
- One Layer Neural Network
- Random Forest
- VADER (current baseline)
- Tabularis AI Multilingual Transformer Model
In all cases, we used default paramaterisation from Scikit-learn to create the models. The hidden layer size of the neural network was set to 384, the same size as the input vector. The tabularis AI model which was originally a 5 class classification model (i.e. Extremely Positive, Positive, Neutral, Negative, Extremely Negative), and our dataset was labelled with 3 classes (Positive, Neutral, Negative), so in this case we merged the categories for extreme and moderate sentiment (So Extremely Positive and Positive are the same category) to align labels.
Results¶
The support vector machine performed the best on the test dataset. This intuitively makes sense as they are specialised for identifying decision boundaries in high-dimensional data. In second place was the neural network, then the random forest. Surprisingly in second last place was the Tabularis AI multilingual transformer model. All models except the Tabularis transformer model achieved an f1 score of approximately 0.6. They also all significantly improved on our older approach of using the VADER model which didn’t perform well on our dataset in any language, tending to classify all our text as neutral (even in English).
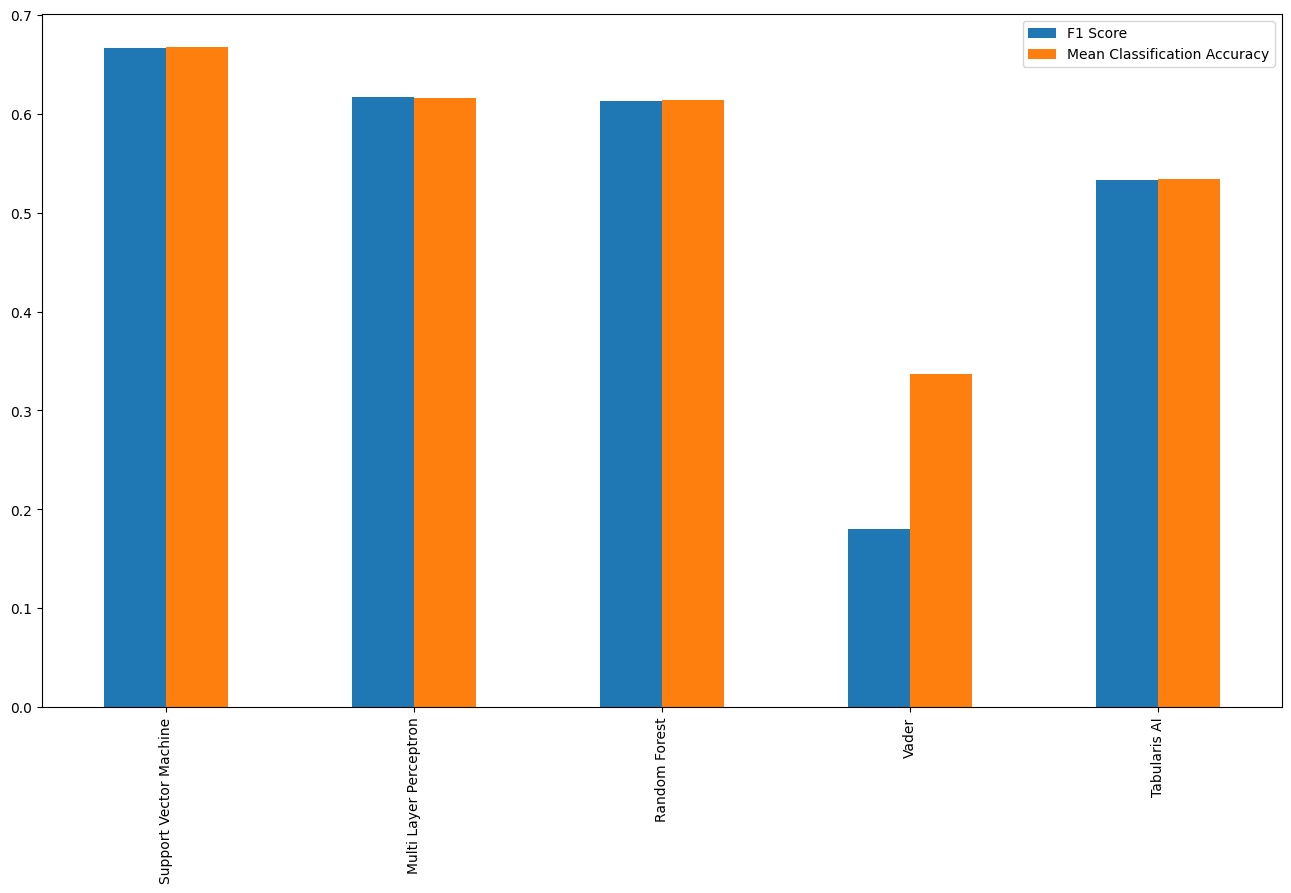
Tabularis AI claim their model achieves a 0.93 train_acc_off_by_one on their validation dataset. “Off by one” accuracy is a type of measurment which allows for a ±1 margin of error in a task. In this case as the original tabularis AI model is a 5 class model, an ‘extremely positive’ string misclassified as ‘positive’ would still count as correct under an ‘off by one accuracy’ measurement. It was very surprising to me that this model scored lower than our own relatively basic approaches using simple and lightweight classifiers like Random Forest. This was a consistent effect across languages, and not limited to the ones which weren’t in their original training dataset, interestingly the Tabularis model didn’t perform notably worse on language it wasn’t trained on (e.g. Indonesian) than ones that it was trained on (e.g. Spanish).
This surprising performance may be due to the training process of the tabularis.ai model, as per their model card their model was:
Trained exclusively on synthetic multilingual data generated by advanced LLMs, ensuring wide coverage of sentiment expressions from various languages.
The Pitfalls of LLM Generated Synthetic Data¶
As I have experienced myself in this project, it is difficult to source diverse enough training data in large enough amounts to develop new and effective models. We’re all exposed to generative AI in our daily lives which can, unsurprisingly, generate a lot of data. It’s tempting to use generative AI models to create synthetic training data. You can easily ask ChatGPT, Claude, or another model to create infinite training examples of labelled text for sentiment classification or other purposes.
Generative AI models like LLMs learn a distribution from their training data - normally sourced from across the internet. They learn an imperfect representation of this data, and can generate new text which (more or less) fits this pattern. Unfortunately for LLM creators, the training data they use contains all kinds of things they would rather their products not repeat verbatim: racism, homophobia, sexism, instructions on how to build explosives, and so on.
In response to this challenge, one popular approach has been a ‘post-training’ step, which trains the model to behave in a way which is acceptable to users and stakeholders but which allows them to generate some data from the original distribution it learned.
When a post trained LLM generates new text, it’s not drawing fom the distribution of its training data, its drawing from a distribution that has been intentionally altered: removing some kinds of content and highlighting others.
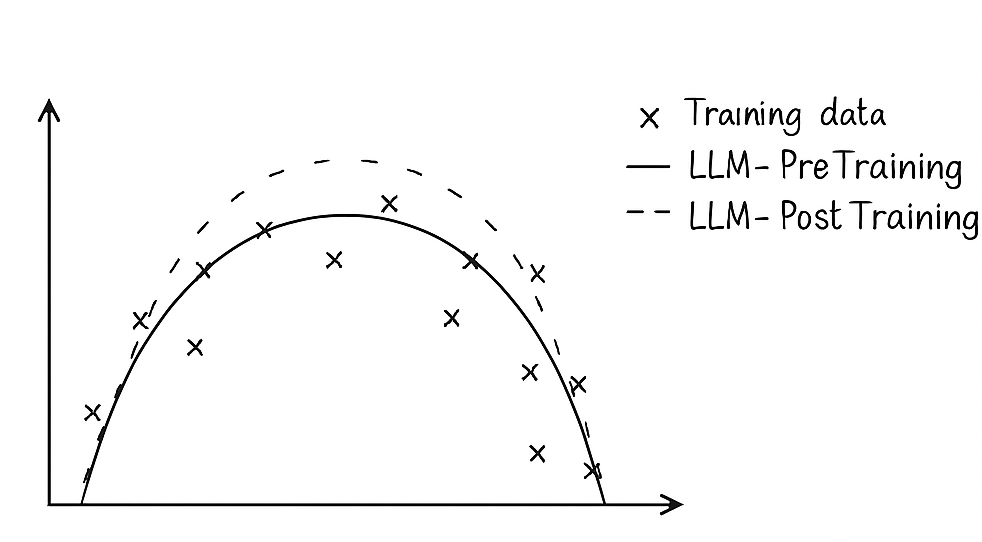
When a sentiment classifier learns from this synthetic distribution instead of real text, it may not find meaningful features to use in its classification process. The relevant features for extremely negative text, for example, may not even be generated by the LLM in the first place, thanks to safety post-training processes. When a classifier trained entirely on this sanitised synthetic data is introduced to real data, it may fail to accurately predict sentiment in even very clear cases.
To make the point, the model classified the (unlikely to be generated by an LLM) phrase "FUCK YOU I HATE YOU DIE as ‘positive’. The alternative more family friendly “I don’t like cheese” was (correctly) classified as ‘negative’.
Takeaways¶
Whilst off-the-shelf models with very high scores may appear to be effective classifiers, its really important to interrogate their performance claims in real-world environment. Developers should also be wary of using entirely synthetic data to train their models, as this synthetic data is unlikely to accurately reflect the environment in which the model will be used.
One surprising component of the results was that the very basic Scikit-learn models performed well even with default parameters. These are much less sophisticated models, but do well in this specialised application that uses transformers for feature extraction.
The performance of a model should also be understood in the context that it will be run in. Our random forest under-performed the others in accuracy, but it was much faster and was barely slower than the existing (fast) VADER model we were using. This makes sense given the computationally simple nature of the decision trees which underlie the random forest model. Speed is very important when processing large volumes of data, the NLP pipeline can become a bottleneck if not properly managed.
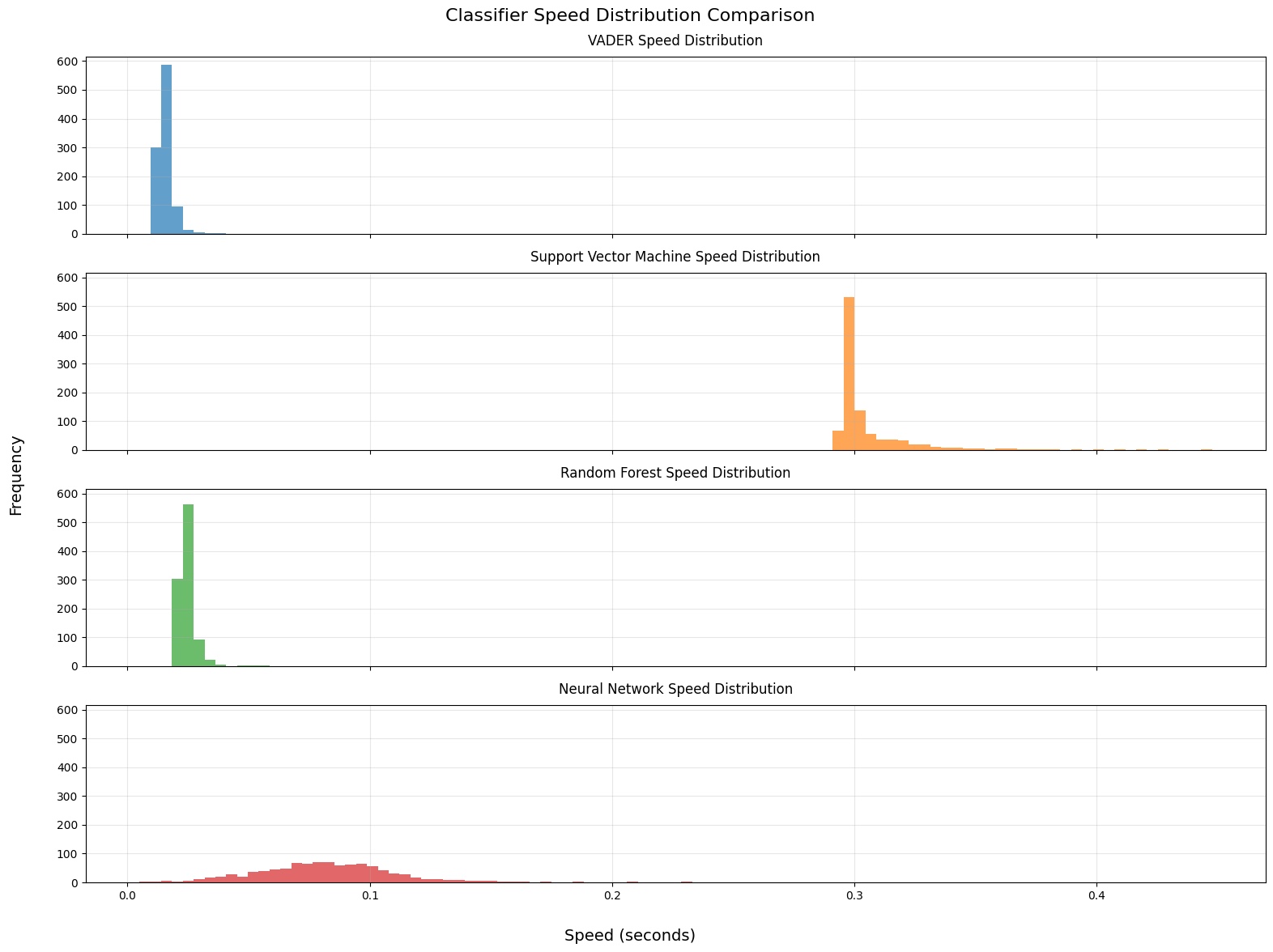
(Full transformer model omitted as it was much slower and skewed the visualisation)
As a result - we felt that the trade-off between accuracy and speed was clear - random forest represented an upgrade in performance with little cost in speed compared to the VADER model we had been using, so we rolled it out across out data ingest pipelines. It is now used in production.
Overall, this was a successful experiment which showed the potential for multilingual embeddings in sentiment analysis across languages, and is an example where the ‘best’ model wasn’t the most accurate, but the one with a good balance of accuracy and speed. It is also a nice example of how relatively large models (Sentence transformers) can work in concert with more specialised non neural models in a real-world context, and of some of the pitfalls of relying too much on synthetic data.